
Optech's Scalable 800G Solution for a 10K H100 LLM Training Cluster
OptechTWOptech's Scalable 800G Solution for a 10K H100 LLM Training Cluster

As AI workloads grow exponentially and demand more compute power, hyperscale data centers are racing to build massive GPU clusters for training trillion-parameter large language models (LLMs). One such project involved a next-generation infrastructure deployment of 10,000 NVIDIA H100 GPUs across a distributed data center environment.
To ensure seamless operation of this AI training fabric, Optech collaborated closely with the hyperscaler's network architects, data center engineers, and AI infrastructure leaders. Together, they developed a customized interconnect strategy that prioritized performance, scalability, and cost-efficiency.
🎯 The Challenge: High-Speed Connectivity at Scale
The key challenges for this deployment included:
-
Sub-microsecond latency for GPU-to-GPU communication
-
2km inter-building distances across the campus
-
Tight budget constraints, with optics and cables making up a large portion of total infrastructure cost
-
Signal integrity and long-term reliability under sustained AI training loads
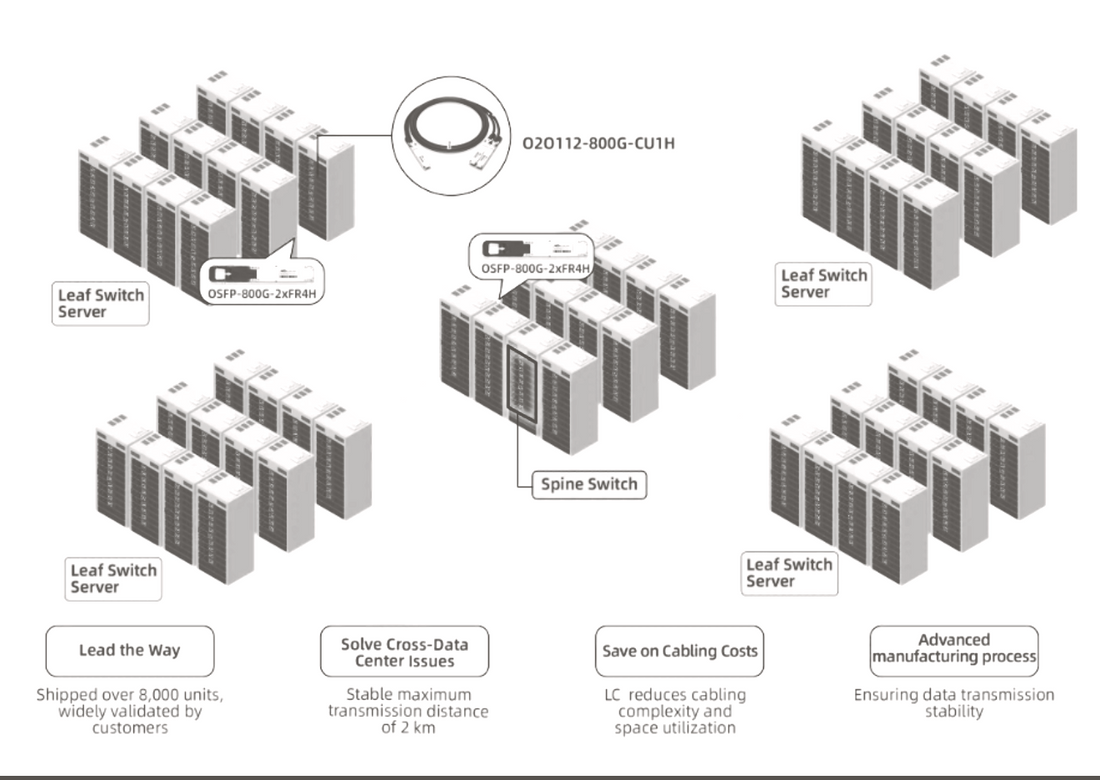
To meet these requirements, Optech proposed a hybrid 800G interconnect architecture using a combination of 800G DAC and 800G 2xFR4 / FR8 optical modules.
🧩 The Solution: Dual-Strategy Interconnect Design
Optech introduced a two-tier strategy to simplify deployment and optimize cost-performance balance based on physical connection distances:
🔌 Leaf-to-Server (Intra-Rack)
-
800G DAC cables
-
Passive copper connections for short-reach links ≤3m
-
Benefits: ultra-low latency, zero power consumption, and minimal cost
🌐 Leaf-to-Spine (Inter-Building)
-
800G 2xFR4 single-mode optical modules
-
High-performance optics supporting distances up to 2km
-
Used for links between spine and leaf switches across different buildings
-
Benefits: Long-reach error-free transmission, compatibility with QSFP-DD and OSFP platforms, and support for future scale-up
In some cases, 800G FR8 modules were proposed to support longer reaches with DWDM capabilities in future expansion stages.
✅ Deployment Highlights
-
✔️ Seamless integration with NVIDIA Quantum-2 InfiniBand switches and H100 GPU nodes
-
✔️ Reduced optical link complexity with fewer cables compared to legacy MPO solutions
-
✔️ Optimized CAPEX by matching each link type with the most cost-effective interconnect
-
✔️ Scalable fabric designed to grow beyond 10K GPUs with minimal hardware overhaul
🌍 Why Optech?
With over 20 years of experience in optical transceiver innovation, Optech delivers purpose-built connectivity for high-performance computing and AI infrastructure. Our 800G optics portfolio includes:
-
800G 2xFR4 & FR8 OSFP/QSFP-DD modules
-
Low-latency DAC & AOC cables
-
Customizable solutions for InfiniBand and Ethernet fabrics
Whether you’re deploying a few racks or scaling to tens of thousands of GPUs, Optech provides the tools to future-proof your AI architecture.
📩 Contact Optech today to discuss your hyperscale AI connectivity needs and request a technical consultation or sample pack.